回顾过去两年 AI 技术的狂飙突进,文本大模型(LLM)的进化路径非常清晰:从最初的“能聊两句”,进化到了如今能够严格遵循格式、调用工具、作为大脑驱动复杂 Agent 的“可编排计算引擎”。
现在,同样的进化正在语音领域发生。
近日,Google DeepMind 携手 Google AI 正式在 Gemini API 预览版中推出了 Gemini 3.1 Flash TTS。如果你仅仅把它看作是“又一个声音更逼真、更好听的文字转语音工具”,那就完全错过了这次更新的真正战略意义。
Gemini 3.1 Flash TTS 的核心亮点并非单纯的拟真度,而是它史无前例地强调 Audio Tags(音频标签)、极其丰富的表达力以及精确的“可控性”。
这标志着一个重要拐点:语音模型正式告别了“输入文本-输出黑盒音频”的古典阶段,进入了像代码一样可以被 Prompt 精细控制的“可编排工作流(Orchestrable Workflow)”阶段。
对于开发者、产品经理和内容创作者而言,这意味着我们在构建 AI Agent、自动化内容生产线以及多模态产品时,终于拥有了一把能够精准雕刻声音的手术刀。
一、为什么我们需要“可编排”的语音?传统 TTS 的痛点
在 Gemini 3.1 Flash TTS 出现之前,我们在应用层使用语音 API 时,通常面临着一种“薛定谔的语气”。
传统的 TTS(Text-to-Speech)模型本质上是一个黑盒:你输入一段带有悲伤情感的文本,期望它用低沉、缓慢的声音读出来。但实际上,模型往往只是机械地将其转化为标准播音腔,或者你需要依赖玄学般的“标点符号控制法”(比如疯狂加句号、省略号来强迫它停顿)。
这种不可控性在产品应用中导致了巨大的摩擦:
- Agent 缺乏“情商”:当你的心理咨询 AI Agent 面对一个正在哭诉的用户时,如果 AI 依然用元气满满、字正腔圆的 AI 播音腔回复:“不要难过,明天会更好”,这种强烈的违和感会瞬间摧毁用户的信任。
- 内容生产无法工业化:在制作有声书或播客时,如果遇到多角色对话,传统 TTS 无法精准区分角色的情绪起伏,导演,也就是创作者,无法像指导真人演员那样,告诉 AI “这里要叹气”“这里要压低声音”。
- 工作流断裂:在多模态应用中,声音无法与画面动作精准对齐,因为你无法控制音频中特定的停顿毫秒数或语速变化。
语音模型要想真正融入复杂的商业和业务工作流,就必须具备像 HTML/CSS 控制网页布局那样的确定性和可编程性。这正是 Gemini 3.1 Flash TTS 想要解决的问题。
二、解析 Gemini 3.1 Flash TTS:当声音拥有了“标签语言”
Gemini 3.1 Flash TTS 之所以能够融入工作流,其核心武器在于 Audio Tags(音频标签)系统。
它不再要求模型去“猜测”文本背后的情绪,而是允许开发者通过结构化的标签,显式地、强力地接管发音的每一个细节。你可以把它理解为语音领域的 Markdown 语法。

在 API 预览中,开发者可以通过类似以下的 Prompt 逻辑来精细控制输出(注:此处为概念演示,具体语法以官方 API 文档为准):
1 | <speak> |
这种控制力带来了三个维度的跃升:
- 细粒度的物理控制:语速(Pace)、音高(Pitch)、停顿(Break),甚至呼吸声(Breath)。声音不再是匀速直线的,而是充满了属于人类的参差多态。
- 高保真的情绪注入:愤怒、悲伤、狂喜、耳语(Whisper),甚至嘲讽。不再需要依赖文本自身的语义,开发者可以直接“命令”模型进入某种情绪状态。
- 非语言符号的融合:笑声、清嗓子、叹气等副语言信息的加入,让合成语音彻底摆脱了“机器味”,具备了真正的表演张力。
三、场景深潜:可编排语音如何重塑三大赛道
当语音变成了可以被代码逻辑随意搓圆捏扁的“材料”后,它将如何在实际应用中爆发出巨大的商业价值?
1. 拟真与高情商的 AI Agent(智能体)
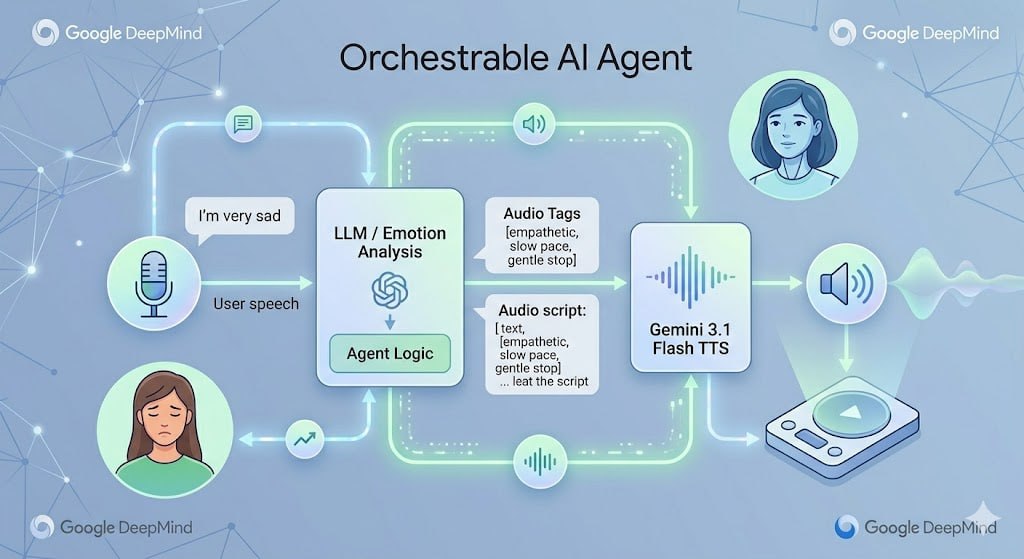
在 Agent 时代,交互界面正在从 GUI(图形界面)向 VUI(语音界面)转移。一个优秀的 Agent 必须是一个优秀的沟通者。
应用案例:动态情绪客服 Agent
过去的 AI 客服只有一种声调,现在的客服 Agent 可以结合 LLM 的情感分析能力,动态调用不同的音频标签。
- 工作流逻辑:用户输入语音,先经 STT 转文本;LLM 分析后发现用户处于“极度愤怒”状态;随后 LLM 生成安抚话术,并同时输出带有
<emotion type="calm"><pace speed="slow">标签的语音请求;最后由 TTS 渲染出极其柔和、带有同理心的声音。 - 商业价值:极大提升交互的真实感和用户留存率。在心理陪伴、语言学习,甚至扮演严厉考官或鼓励型老师的场景里,这种“带情绪的 API”会成为新的基础设施。
2. 工业化的自动化内容生产线(内容引擎)

播客、有声书、短视频配音是 TTS 的传统腹地,但过去的生产方式是“半手工”的:合成音频后再去剪辑软件里疯狂调整。有了可编排的标签,内容生成可以直接进入“代码即成品”的阶段。
应用案例:剧本杀或互动小说的一键音频化
- 工作流逻辑:创作者写好剧本,并通过剧本解析工具自动打上 Audio Tags。例如,系统识别到旁白,就应用
<voice name="narrator" emotion="neutral">;识别到角色 A 濒死的台词,就应用<voice name="characterA" emotion="pain" breath="heavy">。整个几万字的小说,通过一段 Python 脚本,几分钟内就能生成包含丰富音效、情绪饱满的多角色广播剧。 - 商业价值:彻底打破有声读物和精品播客的产能瓶颈。广告公司甚至可以利用同一套文案,通过更改几个参数,瞬间生成 100 个语气不同的音频素材,用于 A/B 测试,寻找最优转化率。
3. 无缝融合的多模态产品工作流(Multimodal Orchestration)
这是最激动人心的一环。当系统中的文本、图像、视频、音频都变成了可被数学描述的实体,它们就可以在同一个时间轴上被精准编排。
应用案例:动态 AI 视频教程生成器
- 工作流逻辑:假设我们要自动生成一段软件操作教程视频。我们不再是先录制视频再配音,而是通过代码定义:“在第 5 秒时,鼠标移动到按钮 X,同时 TTS 播报
<break time="5s"/> 点击这个按钮,你会看到 <pace speed="slow">奇迹发生</pace>。” - 因为语音的停顿、语速变得绝对可控,开发者可以精确计算出这段音频的毫秒级长度,从而反向控制视频画面的切换,实现音画的完美同步。
四、开发者与 PM 避坑指南:如何适应“声音编程”时代?
面对 Gemini 3.1 Flash TTS 等新一代模型,我们的产品设计和开发思维也需要随之升级。
-
从“文本工程”走向“全模态提示词工程”
未来的 Prompt Engineer 不仅要会写指令,还要懂“导演”。你需要学习如何通过组合“叹气”“停顿 200ms”“语速 1.2x”来塑造一个角色的灵魂。建议团队内部建立自己的声音配方库(Voice Preset Library),将经过测试的标签组合沉淀下来,复用于不同场景。 -
工作流解耦:情绪决策与音频渲染分离
在架构设计上,不要把“用什么语气说话”的决策权交给 TTS 模型去猜。更稳妥的做法是,让 LLM 充当“大脑,也就是导演”,负责结合上下文输出文本和对应的 Audio Tags;让 TTS 充当“嘴巴,也就是演员”,只负责精准执行标签指令。这种解耦会显著提升系统的稳定性与可玩性。 -
关注延迟与实时性的平衡
虽然 Audio Tags 带来了极高的控制力,但复杂渲染可能会增加一定的首包延迟。在构建实时通话应用,比如语音打车助手时,需要谨慎评估插入过多标签对响应速度的影响,优先保证流畅度;而在异步内容生成,比如生成第二天早晨的专属新闻播客时,则可以火力全开,追求极致表现力。
五、结语:计算范式的延伸
Gemini 3.1 Flash TTS 及其强调的 Audio Tags 功能,看似只是 API 文档上的几行新参数,但其背后隐藏着巨头对 AI 发展路径的深刻理解:不可控的生成只是一次性的玩具,可精确编排的生成才是重塑千行百业的工具。
当声音像代码一样可以被调用、组合、复用时,我们实际上是将人类最古老、最微妙的沟通方式,也就是语音,正式纳入了现代软件工程的版图。
对于站在潮头的产品构建者来说,是时候放下旧有的“TTS 只是个发音工具”的偏见,开始思考如何用这一行行充满情绪、呼吸和停顿的代码,去编织下一个划时代的数字产品了。