2026年4月2日,Google DeepMind在X平台上正式发布Gemma 4开源模型家族。这一次,他们直接把"字节对字节最强开源模型"的标签打了出来。Gemma 4全系采用Apache 2.0许可协议,任何开发者、企业甚至个人都能自由下载、修改、商用、部署,完全没有以往开源模型常见的商业限制。这意味着,你可以在自己的笔记本电脑、手机甚至树莓派上运行曾经只有云端大模型才能驾驭的高级推理和自主代理工作流。Gemma 4不是简单的参数堆砌,而是DeepMind从Gemini 3研究中提炼出的"每参数智能"极致优化成果,真正把前沿AI带到了每个人身边。
Gemma家族的进化之路:从Gemma 1到Gemma 4的跨越
Gemma系列自2024年首次亮相以来,就以"轻量级、高性能、开源"著称。Gemma 1(2B/7B)奠定了基础,Gemma 2和Gemma 3逐步加入多模态、长上下文和边缘优化。而Gemma 4则是质的飞跃:它直接继承Gemini 3的核心技术,在架构上实现"智能密度"最大化,同时覆盖从手机到工作站的全场景需求。相比前代,Gemma 4在数学、编码、科学知识和代理工具使用上的表现实现了断层式提升。例如,在AIME 2026数学基准上,31B模型从Gemma 3的20.8%跃升至89.2%;LiveCodeBench编码竞赛中从29.1%飙升到80.0%。这些数字不是营销话术,而是真实跑分。
DeepMind CEO Demis Hassabis在发布时直言:"Gemma 4是各自尺寸下全球最强的开源模型。"这句话的底气,来自四个精心设计的变体,以及对"代理时代"需求的精准预判。
四款模型,覆盖全场景:从边缘设备到本地服务器
Gemma 4一口气推出四款型号,参数规模和架构各有侧重,满足不同硬件条件下的极致性能:
31B Dense(31亿参数稠密模型)
这款是Gemma 4的性能王牌,专为高级本地推理任务打造。它在Arena AI文本榜单上排名全球开源模型前三,能与参数量大20倍的模型正面硬刚。适合构建自定义代码助手、科学数据集分析、复杂多步规划等场景。在个人工作站或高配GPU上运行,经过4-bit量化(Q4_0)后仅需约17.4GB显存,普通开发者也能轻松上手。
26B MoE(26亿参数混合专家模型,激活约4B)
MoE架构让它在推理时只激活少量参数,却保持了极高吞吐量。在Arena榜上位列第6,延迟表现优秀,非常适合需要实时响应的本地AI服务器。内存占用更低(Q4_0约15.6GB),却能处理完整代码库或长对话历史。开发者反馈,这款模型是"消费级硬件上最接近云端智能"的选择。
E4B(Effective 4B,有效4亿参数边缘模型)
针对移动和轻量设备优化,采用Per-Layer Embeddings(PLE)技术进一步压缩。支持实时文本、视觉和音频处理,能在手机上实现离线语音助手、图像理解或视频帧分析。BF16模式下内存约15GB,Q4_0仅5GB,适合Pixel手机、Chrome浏览器甚至Jetson Nano。
E2B(Effective 2B,有效2亿参数超边缘模型)
最轻量级选手,Q4_0量化后仅需3.2GB内存!可在树莓派5上以每秒133 tokens的预填充速度运行,完美适配IoT、智能家居、机器人控制等场景。它同样支持音频输入,真正实现了"手机上就能对话、看图、听声"的多模态体验。
所有模型均支持多模态输入:文本+图像+视频(帧序列),E2B/E4B还原生支持音频。上下文窗口更是亮眼——31B/26B高达256K(可容纳整本代码库或数小时对话历史),边缘模型也达到128K,彻底解决长序列遗忘问题。
核心亮点:原生代理能力与工具调用
Gemma 4不是聊天机器人,而是为"自主代理(Agentic Workflows)"量身打造。它内置原生函数调用(function calling)、结构化JSON输出和系统指令支持,代理可以自主规划、调用API、搜索数据库、执行多步任务,而无需额外微调。这在τ2-bench代理工具使用基准上体现得淋漓尽致:31B模型得分86.4%,远超前代6.6%。想象一下:在本地运行一个能"看屏幕、听语音、操作App、生成报告"的私人助理,所有数据永不出本地,隐私安全拉满。
此外,Gemma 4支持140+语言,覆盖全球开发者需求。安全方面,它继承了Gemini系列的严格过滤和对齐机制,提供透明、可审计的权重,适合企业级Sovereign AI部署。
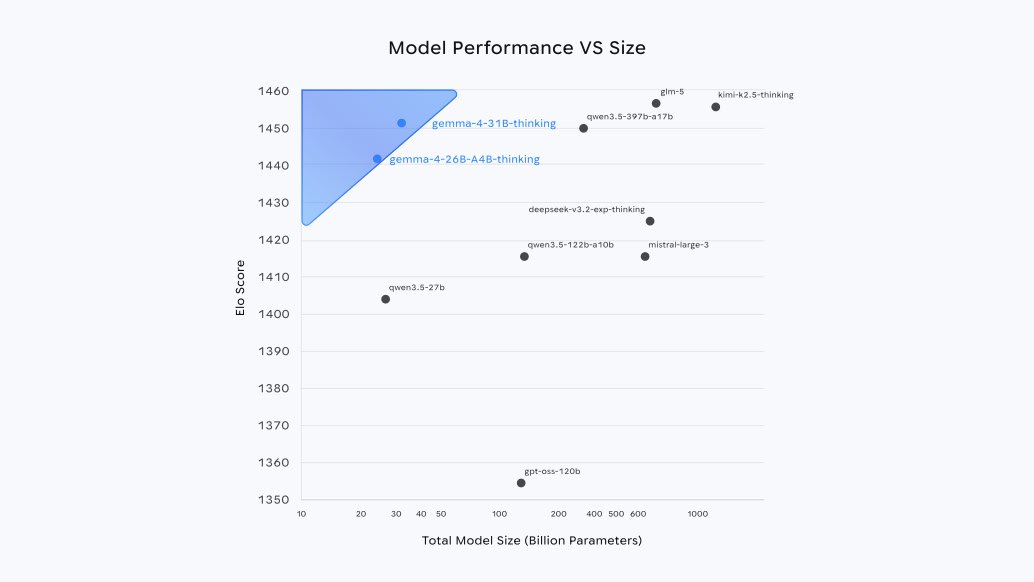
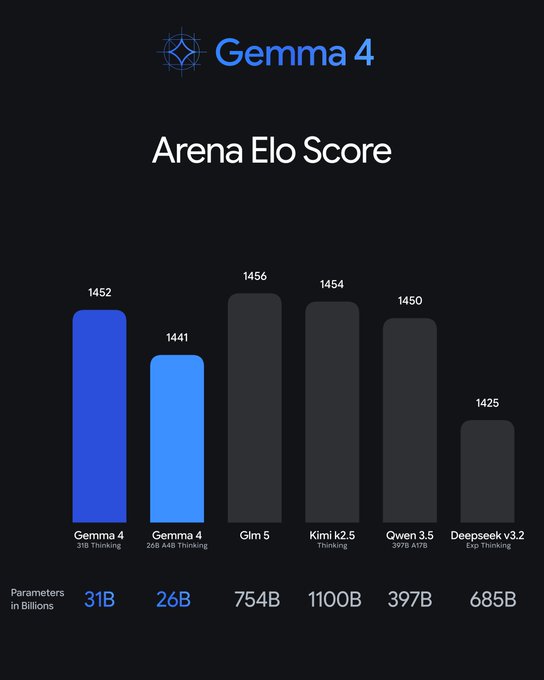
基准表现:小模型打败大模型的"每参数智能"
Gemma 4在多个关键基准上刷新开源纪录(Thinking模式下):
- Arena AI(文本):31B达1452,26B达1441,远超Gemma 3 27B的1365。
- MMMLU多语言问答:31B 85.2%,E4B仍有69.4%。
- MMMU Pro多模态推理:31B 76.9%。
- GPQA Diamond科学知识:31B 84.3%。
这些成绩证明:Gemma 4不是靠参数堆,而是靠架构创新(高效MoE、PLE、RoPE优化等)实现了"智能密度"突破。社区已经有人用Unsloth在几小时内量化并跑通GGUF版本,速度飞起。

如何快速上手:零门槛开发体验
Gemma 4的开放程度前所未有:
- Google AI Studio:直接在线试用31B/26B,支持Prompt工程和原型验证。
- Google AI Edge Gallery:专为E2B/E4B提供移动端演示。
- 下载平台:Hugging Face、Kaggle、Ollama一键获取权重。NVIDIA NIM、vLLM已优化支持,AMD GPU和Google Cloud TPU也无缝兼容。
- 量化与部署:官方提供BF16、SFP8、Q4_0等多种格式,结合Ollama或LM Studio,几分钟就能在本地启动服务器。
- 微调:LoRA、QLoRA等高效方法让普通显卡也能定制专属模型。
社区已涌现大量变体:代码专用、医疗专用、多语言增强版。4000万+历史下载量表明,Gemma生态正呈指数级增长。

深远影响:本地AI、隐私保护与开源新纪元
Gemma 4的发布标志着AI从"云端垄断"转向"本地民主"。以往,企业担心数据泄露、API费用和供应商锁定;现在,你可以用免费开源模型构建生产级代理系统。隐私敏感行业(如医疗、金融、法律)将迎来爆发:所有推理在本地完成,无需上传敏感数据。
对开发者而言,这意味着更低的成本、更快的迭代和无限创意空间。想象一下:手机上的实时翻译+视觉助手、笔记本上的全栈代码审查Agent、边缘设备上的智能监控系统……这些曾经的科幻场景,如今只需几行代码就能实现。Apache 2.0许可更是解除了所有法律顾虑,企业可放心商用、二次开发甚至售卖衍生产品。
当然,挑战依然存在:如何设计可靠的Agent控制机制?如何平衡本地算力与性能?但Gemma 4已把"门槛"拉低到历史最低点。Google正与Qualcomm、MediaTek合作,进一步优化移动端体验,未来Pixel手机或Chromebook将直接预装Gemma Edge能力。
结语:开源AI的黄金时代已来
Gemma 4不是一款模型,而是一场本地AI革命的宣言。它证明:顶级智能无需依赖云端,也无需牺牲隐私或支付高昂费用。DeepMind用实际行动兑现了"与开发者共建AI未来"的承诺。无论你是独立开发者、创业团队还是大企业工程师,现在正是下载Gemma 4、启动你的第一个本地代理项目的最佳时机。
未来已来,就在你的硬件上。去Hugging Face拉取权重,开始构建属于自己的AI世界吧!Gemma 4,让每一个人都能成为AI时代的创造者。